AnalysisAI Models
Jun 17, 7:44 AM
MiniMax Sparse Attention reduces quadratic cost of long-context attention
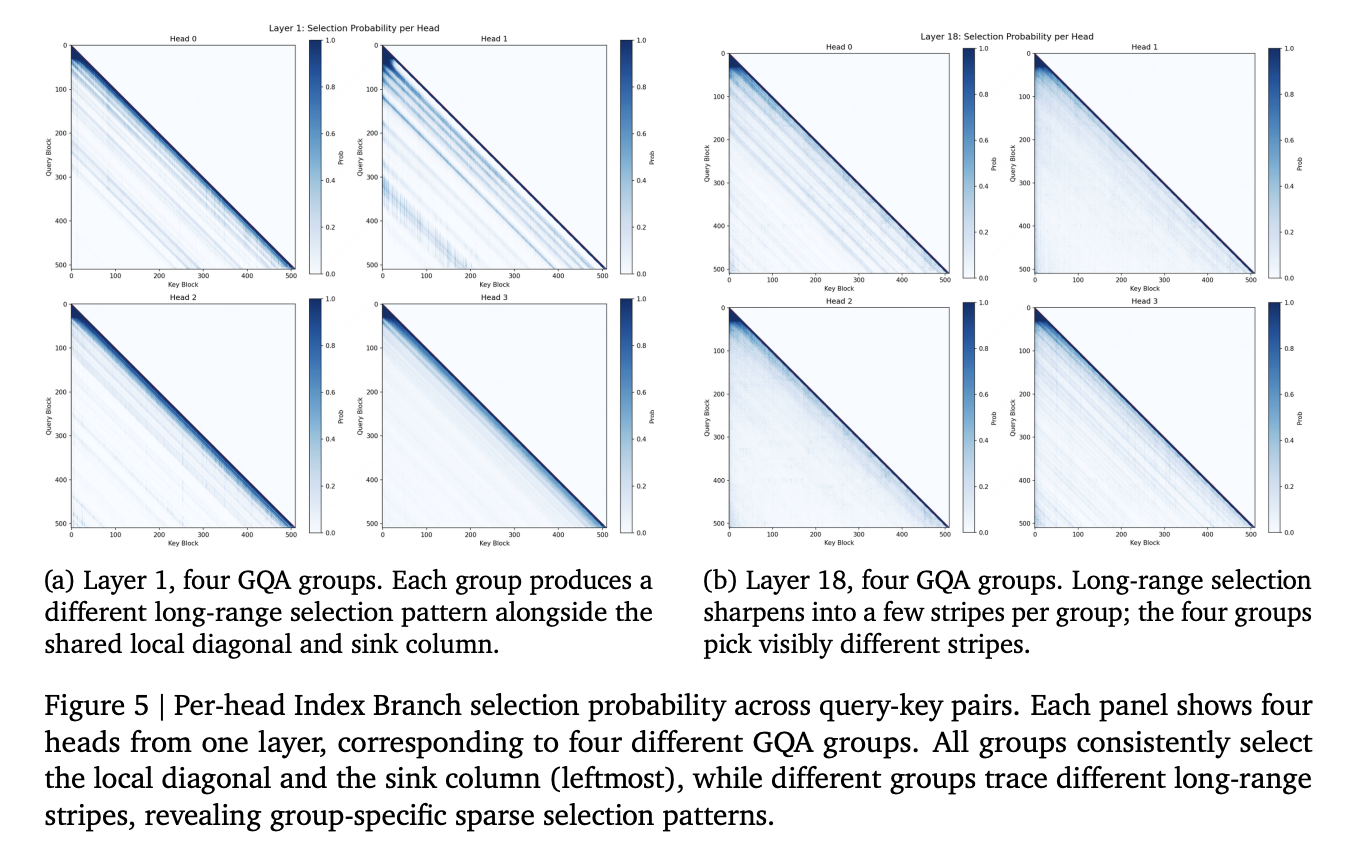
The MSA method, built on Grouped Query Attention, was tested inside a 109B-parameter MoE model trained on 3T tokens. It targets the quadratic cost bottleneck of softmax attention at long contexts.
·
Jun 17, 7:44 AM