AnalysisAI Models
15 days ago
Real-time LLM inference achieves 3k tokens/s on standard GPUs
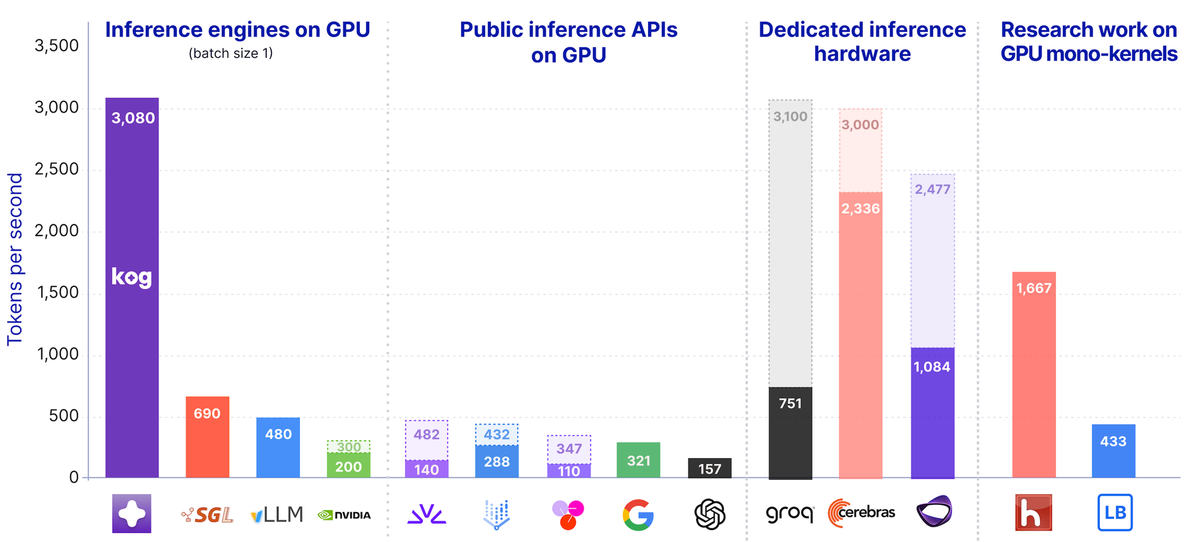
A blog post from Kog AI claims 3,000 tokens per second per request for LLM inference on standard GPUs. The method enables real-time performance without specialized hardware.