AnalysisAI Models
2 days ago
Research cuts LLM context 16x without accuracy loss
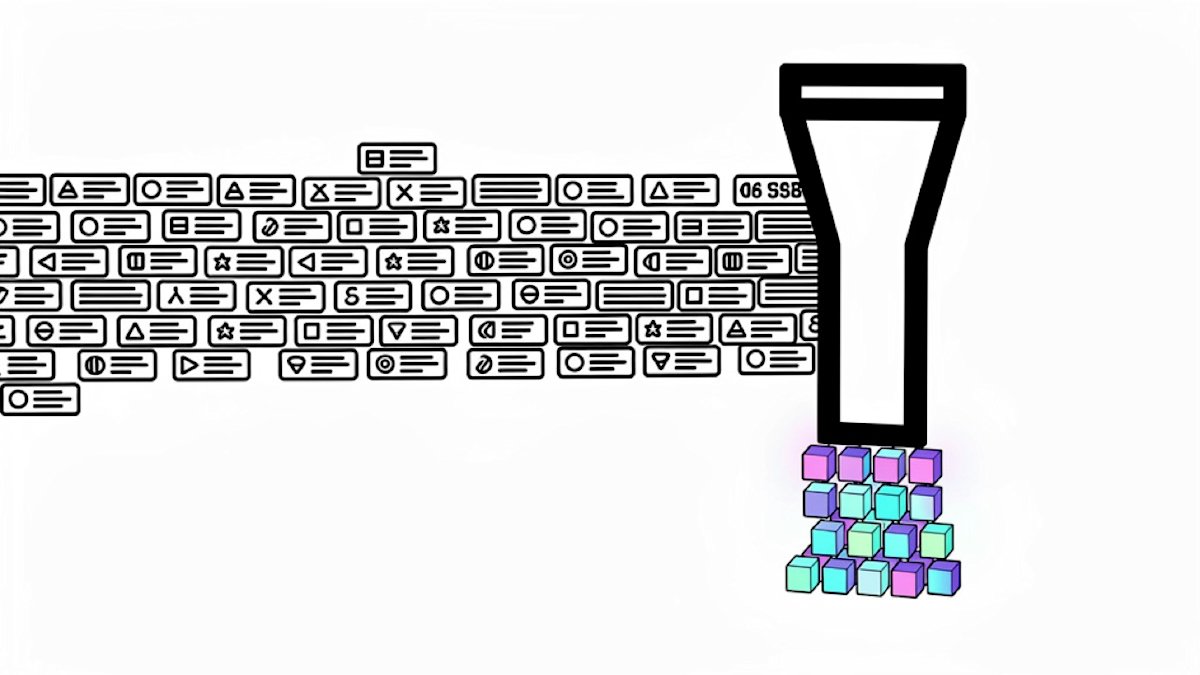
New research achieves 16x compression of LLM context windows without accuracy degradation, solving the computational bottleneck of growing token counts in long-running agents. Unlike prior methods that hurt accuracy, this technique preserves model quality while cutting memory and compute.
2 days ago