AnalysisAI Models
Jun 18, 9:14 AM
KV cache compression race: TurboQuant, OSCAR, EpiCache compared
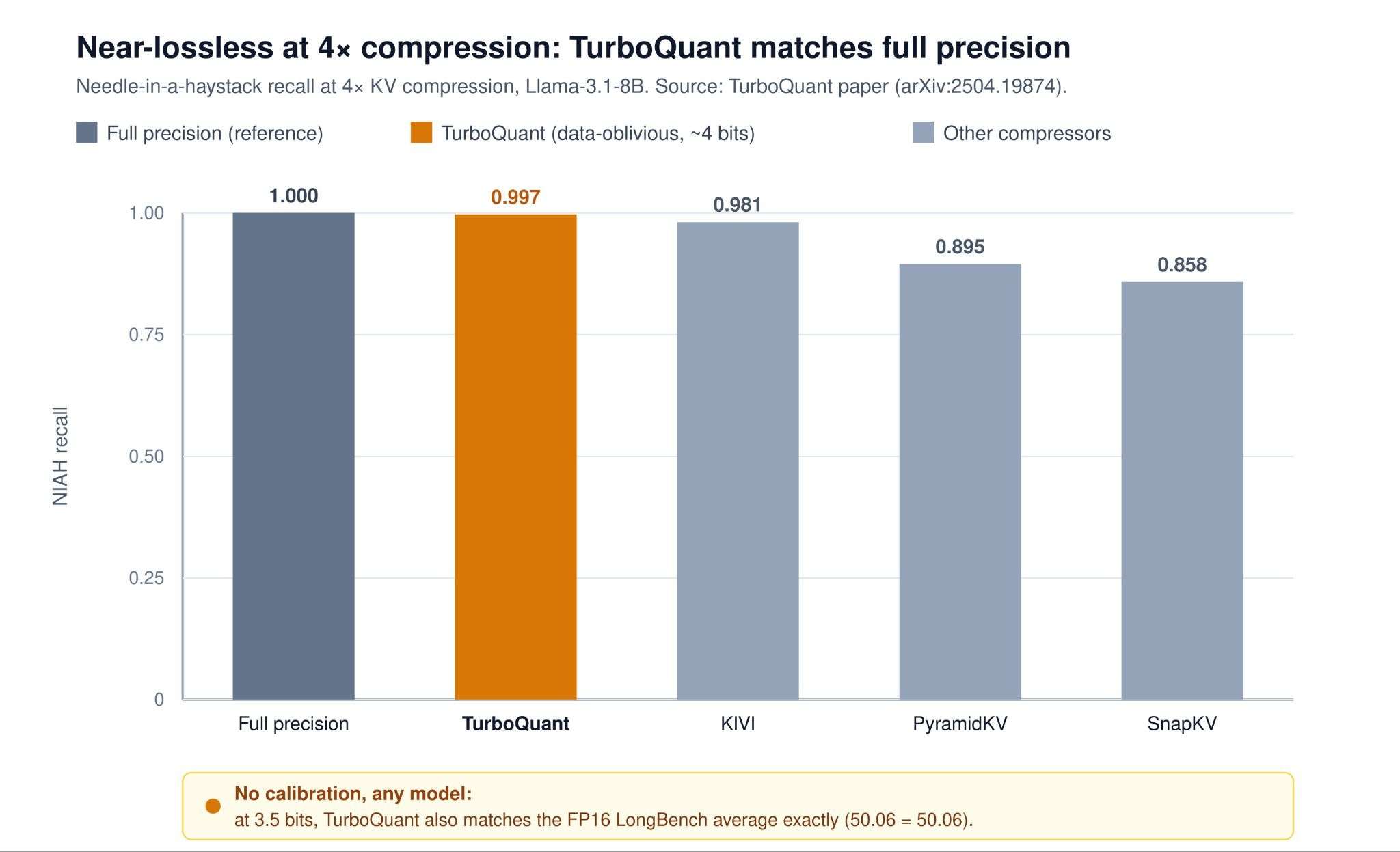
KV caches grow linearly with sequence length, creating a memory bottleneck during LLM inference. The article compares three compression techniques: TurboQuant, OSCAR, and EpiCache.
·
Jun 18, 9:14 AM