AnalysisAI ModelsDevelopers
2 hours ago
TurboQuant, OSCAR, and EpiCache compared for KV cache compression
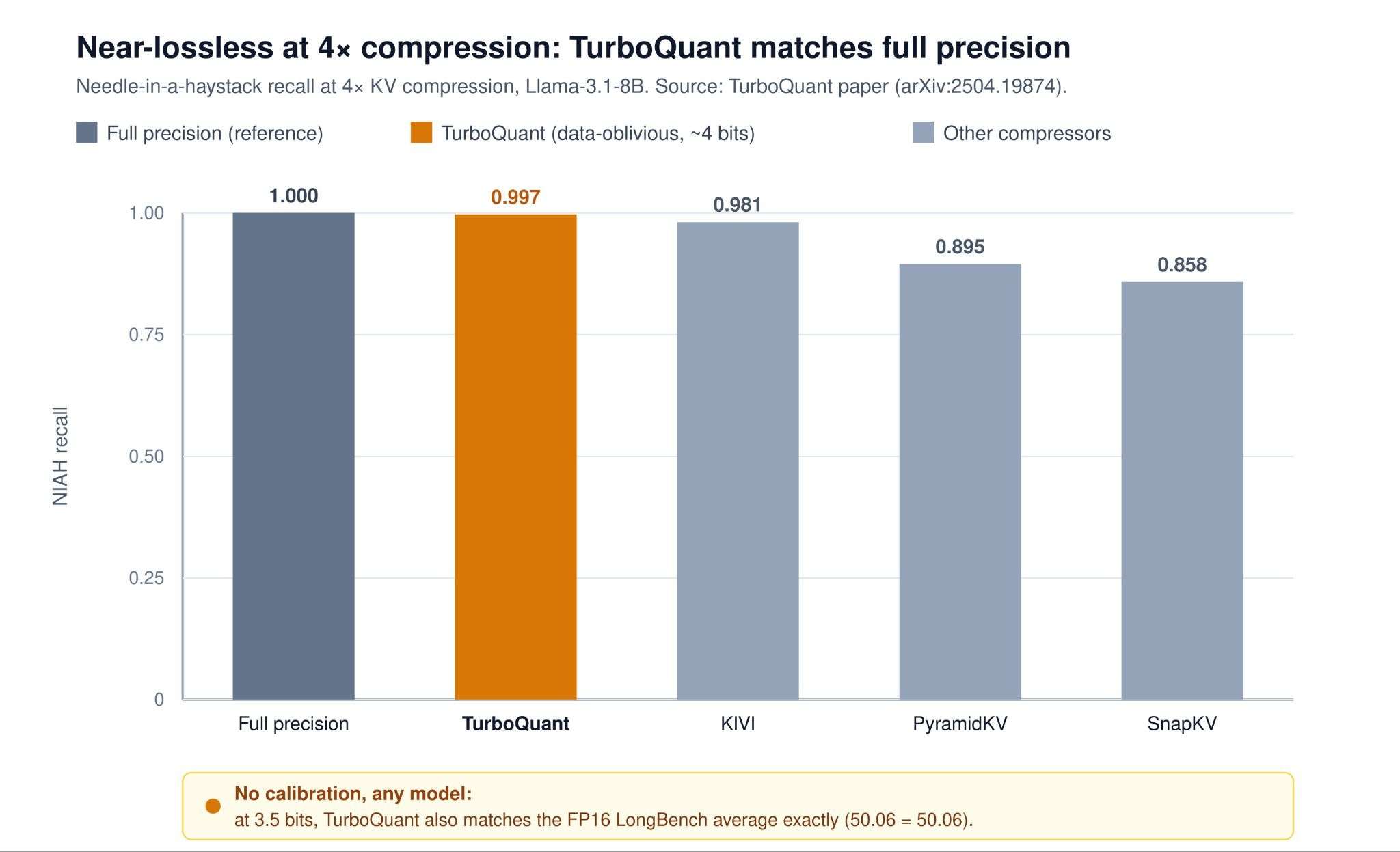
TurboQuant uses quantization-aware training, OSCAR uses adaptive sparsity, and EpiCache uses eviction policies, targeting long-context LLM memory bottlenecks. The article benchmarks each method on memory savings and inference speed.
·
2 hours ago