AnalysisAI Models
3 days ago
LLM context compression at 16x beats KV cache
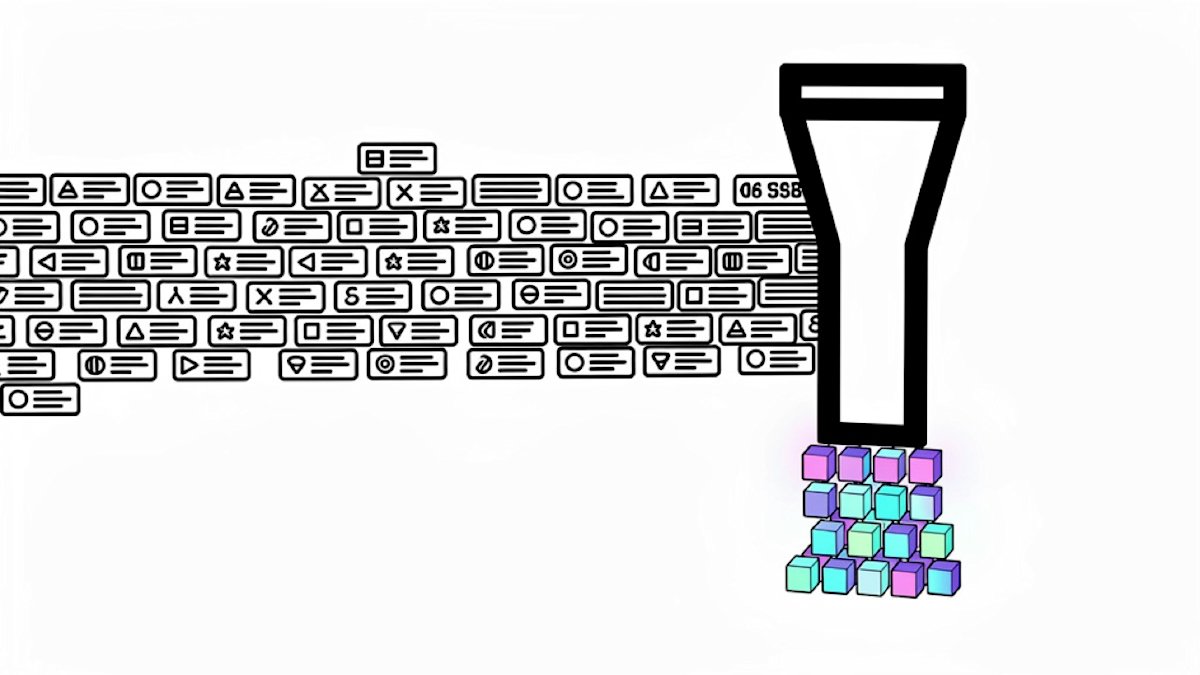
Researchers achieved 16x context compression for LLMs without accuracy loss, outperforming traditional KV cache methods. The technique is production-ready.
Researchers achieved 16x context compression for LLMs without accuracy loss, outperforming traditional KV cache methods. The technique is production-ready.