AnalysisAI Models
3 hours ago
MiniMax introduces Sparse Attention (MSA) for efficient long-context MoE
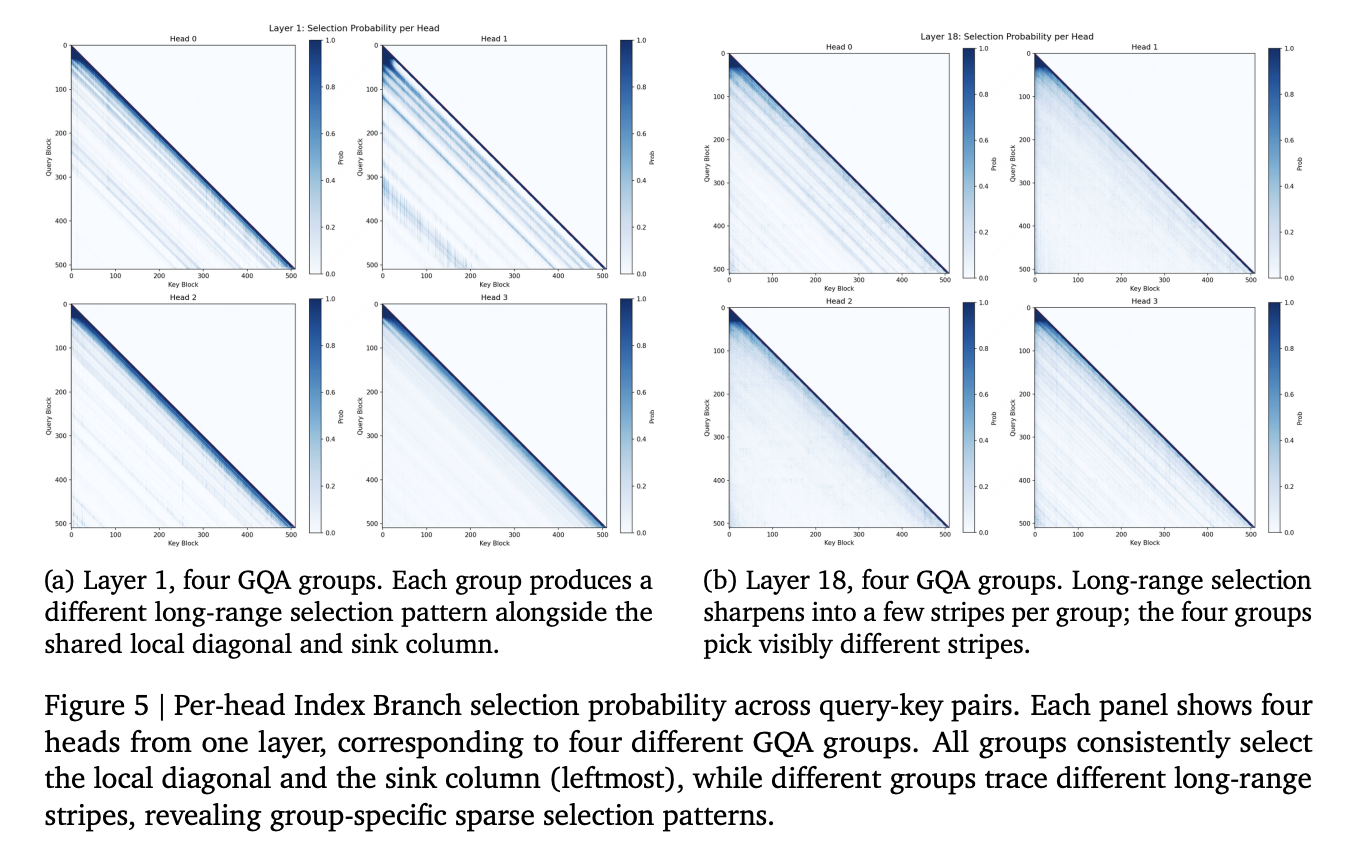
MSA is a two-branch block-sparse attention method built on GQA, trained on a 109B-parameter MoE model with a 3-trillion-token budget. It targets the quadratic cost of softmax attention at long context.
·
3 hours ago