AnalysisDevelopersAI Models
Jun 22, 8:00 PM
JetSpec: Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting
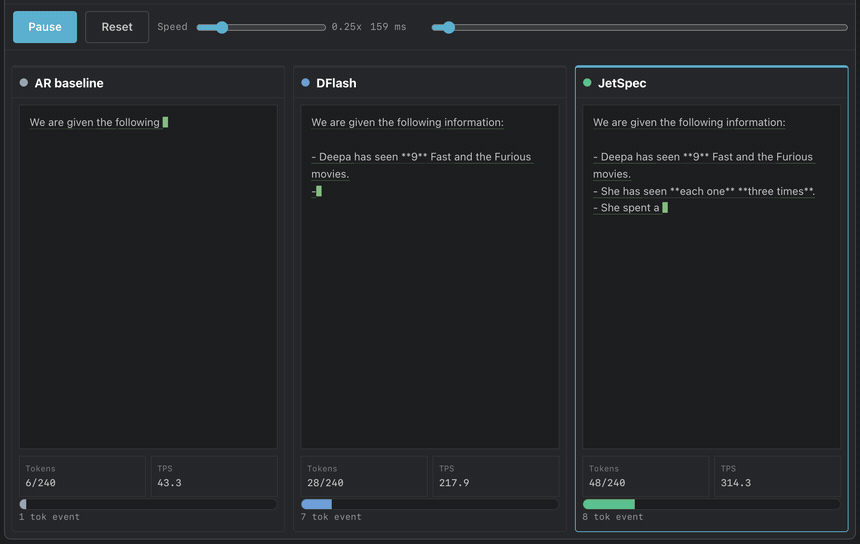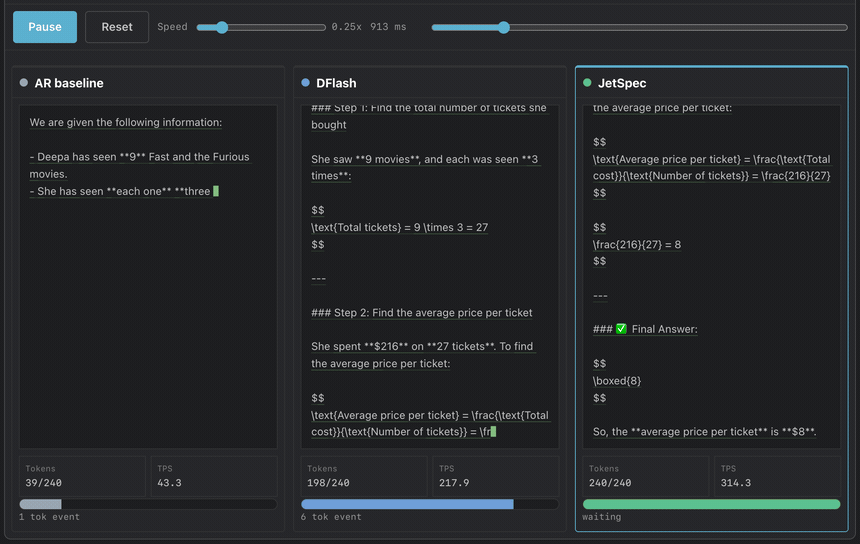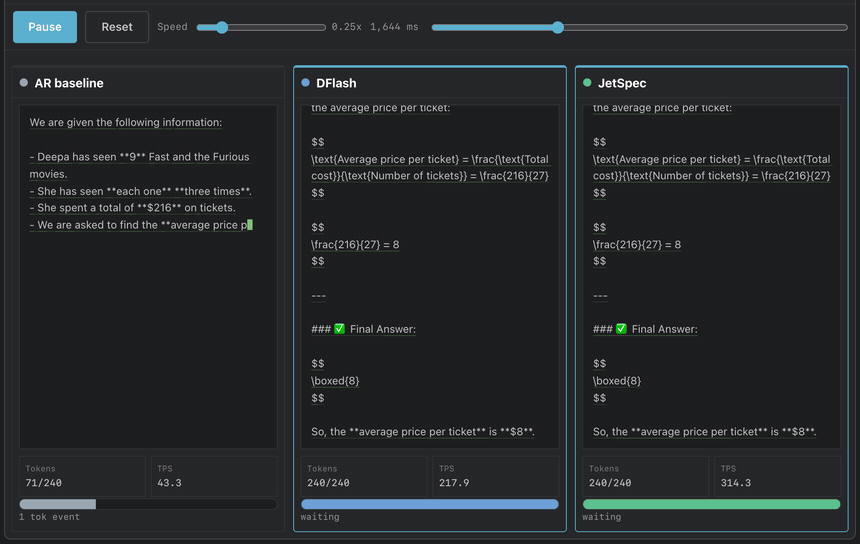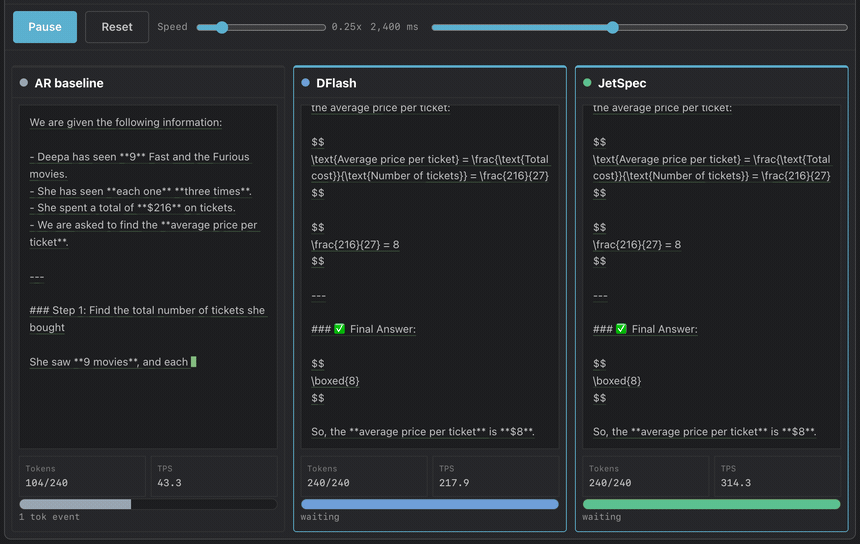
On Qwen3-8B, greedy decoding with budget 256, JetSpec achieves 9.64x speedup on MATH-500 and 4.58x on open-ended chat, verified losslessly in one forward pass. Throughput reaches ~1000 TPS on a single B200 GPU. JetSpec trains a causal parallel draft head over fused hidden states from a frozen target model.
Jun 22, 8:00 PM